

DeepSeek推出V3.2与V3.2-Speciale,开源“大模型Agent”迈入新阶段

 114
来源: 华景图数字科技
114
来源: 华景图数字科技
杭州—2025年12月1日—国内领先的人工智能研究机构DeepSeek正式对外发布其最新大模型版本DeepSeek-V3.2与DeepSeek-V3.2-Speciale。此次双版本并行推出,标志着DeepSeek在“通用大模型+Agent化能力”方向上的一次全面升级,也意味着开源模型在性能与工程化实用性方面的又一次重大跃升。
一、模型定位与差异
DeepSeek-V3.2:作为V3系列的新正式版本,该模型旨在“通用+实用”,兼顾推理能力、长文本处理效率以及工具调用能力。官方指出,V3.2在常规问答、内容生成、Agent场景中的表现可比肩当前闭源顶级模型的“日常使用水准”。
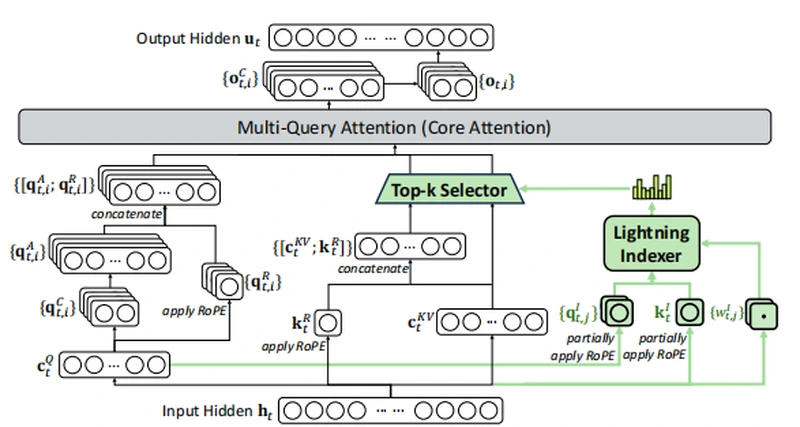
图1 DeepSeek-V3.2 的注意力架构
DeepSeek-V3.2-Speciale:这是面向高复杂度推理、高难度任务与研究/工程应用场景的高算力版本。Speciale版本在国际数学与信息学竞赛等推理基准测试中表现尤为突出—DeepSeek发布资料显示,其在2025年International Mathematical Olympiad(IMO)、International Olympiad in Informatics(IOI)等赛事中达到了“金牌级”推理水平。

图2 DeepSeek-V3.2及其同类产品的基准测试
二、技术亮点与创新
推理+Agent能力融合:V3.2是DeepSeek首个将“思考(thinking)”机制与“工具调用(tool-use)”能力融合到一个模型中的版本,支持在“思考模式(thinking mode)”下进行多轮复杂推理与工具协同,也可在“非思考模式”下提供高效、快速响应。
长上下文+效率优化:据其技术报告,新模型采用了名为DeepSeek Sparse Attention (DSA)的稀疏注意力机制—在处理长文本时显著降低计算与内存开销,同时保持模型性能。
大规模训练/强化学习+合成任务数据:DeepSeek表示其通过大规模的agent-task合成训练(覆盖数千环境、数万复杂任务),强化了模型在复杂指令、多步任务、逻辑推理与工具调用时的稳定性与泛化能力。

图3 在API场景中的思维保留机制
三、市场与产业影响
此次发布立即引起产业与开发者广泛关注。多家媒体指出,DeepSeek-V3.2可作为“高性价比大模型+ Agent平台”的代表—对比闭源大型模型,其以开源+高性能+较低资源消耗组合抢占了中小企业、初创团队以及研究机构用户群。
同时,Speciale的高推理能力和技术爆发,也意味着开源模型在数学、编程、科学研究、复杂问答等“硬核智力任务”上的可行性大幅提升—对学术研究、自动化工具、智能助理、代码生成/验证等高价值场景具有潜在推动作用。
业内评论认为,DeepSeek这次发布再次强调:在大模型竞争中,开放、可定制、工程化能力+性能的组合,正在成为开源阵营挑战闭源巨头的新制高点。
作为国内AI初创公司在大模型、Agent能力与开源策略上的重要尝试,DeepSeek-V3.2与V3.2-Speciale的发布,不仅是技术上的一次跃进,也具有重要的产业导向意义。它提醒业界:大模型竞争的下一阶段,可能不再只是“谁更大、谁参数多”,而是“谁能在开源、效率、工程化、场景适配与智能Agent能力上达到平衡且具落地能力”。未来,开源模型与闭源模型之间的边界正变得越来越模糊—而这,对整个AI生态,都可能带来深远影响。
